
External Authentication¶
For a serious production installation, you will want to provide not only builtin users, but integrate Dataverse with existing authentication providers run by your corporation or firms like ORCID, GitHub, Google etc.
Upstream documentation names a few possibilities:
Below you can find a description how to use them within a Kubernetes deployment.
OAuth2 and OpenID Connect providers¶
The linked Dataverse installation guide sections above already explain the back and forth plus differences between the two related options. In terms of configuration they are rather similar, so lets head over.
Authentication providers are configured via JSON objects in Dataverse, being pushed to an API endpoint to configure and enable.
While you could simply deploy your authentication provider configuration manually, this is not sustainable nor follow it best practices like GitOps and DevOps.
To store and deploy the configuration in a secure and sustainable way, we do the following:
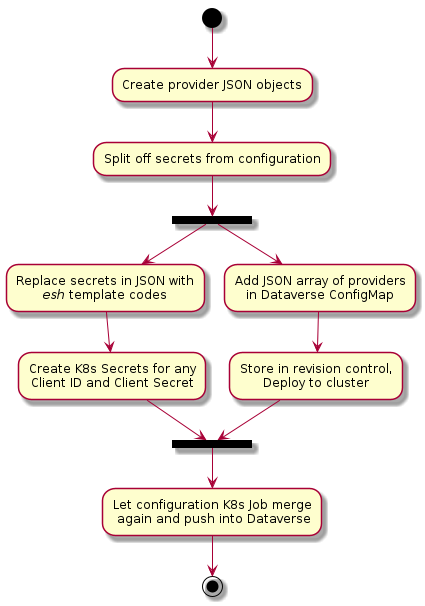
Add providers to ConfigMap¶
To create a configuration usable in your Kubernetes deployment, simply add them
to your Dataverse ConfigMap, familiar from Configuration, as shown in
the below example.
Again, please make yourself familiar with upstream documentation about OpenID Connect and OAuth2.
---
kind: ConfigMap
apiVersion: v1
metadata:
name: dataverse
data:
AUTH_PROVIDERS: |
[
{
"id": "github",
"factoryAlias": "oauth2",
"title": "GitHub",
"subtitle": "",
"factoryData": "type: github | userEndpoint: NONE | clientId: <%= $(cat $SECRETS_DIR/providers/github_clientid) %> | clientSecret: <%= $(cat $SECRETS_DIR/providers/github_clientsecret) %>",
"enabled": true
},
{
"id": "orcid",
"factoryAlias": "oauth2",
"title": "ORCID",
"subtitle": "",
"factoryData": "type: orcid | userEndpoint: https://api.sandbox.orcid.org/v2.0/{ORCID}/person | clientId: <%= $(cat $SECRETS_DIR/providers/orcid_clientid) %> | clientSecret: <%= $(cat $SECRETS_DIR/providers/orcid_clientsecret) %>",
"enabled": true
}
]
Important
You need to provide your JSON array of providers as
AUTH_PROVIDERSkey, otherwise the configuration script cannot find them.Split off the secret values for
clientIdandclientSecret. See below.
Add Secrets for credentials¶
Now let’s create a secret with all our shiny access credentials for the external authentication services we use. Please remember to read Credentials and Secrets, too, to be on the safe side with your confidential data.
---
apiVersion: v1
kind: Secret
metadata:
name: dataverse-providers
type: Opaque
stringData:
github_clientid: xxxx
github_clientsecret: xxxx
orcid_clientid: yyyy
orcid_clientsecret: yyyy
Align Jobs, Secret and ConfigMap for merging¶
Our Job Kubernetes objects for configuring and bootstrapping Dataverse by
default try to mount the dataverse-providers secret at $SECRET_DIR/providers
(see also dataverse-k8s image), but do it optionally.
The configuration job uses esh to merge back
the secret values into the JSON provider objects from the ConfigMap. We
simply read the values from the secret files mounted by Kubernetes and push
the merged provider configurations to Dataverse with curl.
So make sure that your file path to the secret files match with the key values in your secret. See matching example above.
Hint
As always, your Secrets should be mounted as volumes. We consider this
as a safe default and will only support this kind of usage.
SAML using Shibboleth Service Provider¶
Many institutes from R&D and higher education are part of the worldwide SAML-based edugain AAA federation.
While this is a great idea, there are two problems:
A federation design drawback: Dataverse relies completely on the fact that the SAML identity provider will provide all attributes like names, email etc. This is not always the case within the federation, depending on the decisions taken in the individual institutions. There are guidelines, but in real life, things are tough and admins don’t have lots of resources for remote partners. See also https://wiki.geant.org/display/eduGAIN/IDP+Attribute+Profile+and+Recommended+Attributes
Shibboleth is perfectly suited for use as an identity provider.
Running it as a service provider for Dataverse on a Kubernetes deployment is a bad idea. It violates best practices of one service per container and locks you into an Apache-based reverse proxy. You will want to avoid that by all means on Kubernetes cluster.
Please find us on IRC to discuss further.

SAML using an Identity Management Service¶
Please see above for OpenID Connect support hooking into Dataverse to attach to such services integrated in SAML federations.